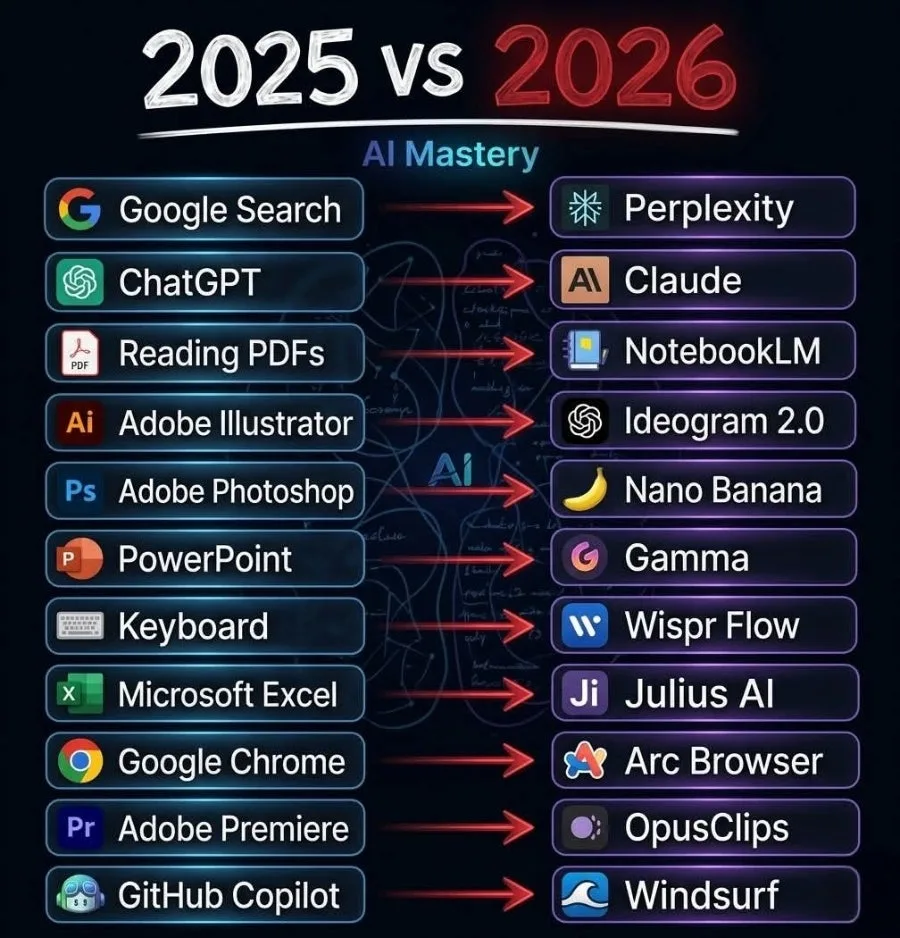
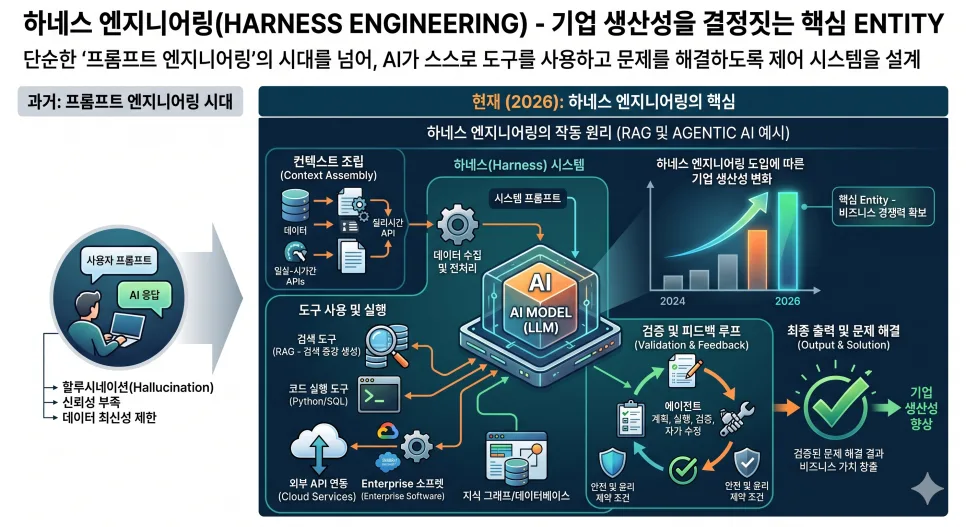
Deep Agents 프레임워크에서 서브에이전트(SubAgent)는 복잡한 작업을 효율적으로 분담하고 자동화하는 핵심 개념입니다. 여러 기능을 가진 하나의 에이전트보다 검색, 분석, 요약 등 특정 역할에 특화된 서브에이전트를 활용하면 전체 시스템의 안정성과 명확성을 높일 수 있습니다. 2026년, AI 에이전트 개발에서 서브에이전트의 중요성은 더욱 커질 것입니다.
서브에이전트란 무엇이며 왜 필요한가요?
서브에이전트는 메인 에이전트가 특정 작업을 수행해야 할 때 호출하여 전문적인 역할을 맡기는 하위 에이전트를 의미합니다. 예를 들어, 메인 에이전트가 질문을 이해하고, 검색하고, 결과를 해석하며, 보고서를 작성하는 모든 과정을 직접 처리하는 대신, 검색 전용 서브에이전트, 분석 전용 서브에이전트 등으로 역할을 분담할 수 있습니다. 이러한 구조는 하나의 에이전트에 과도한 부담이 집중되는 것을 방지하고, 각 서브에이전트가 특정 작업에 최적화되어 더 높은 효율과 정확성을 발휘하도록 합니다. 복잡한 작업을 체계적으로 분리하여 관리하는 것이 서브에이전트 도입의 핵심 목적입니다.
서브에이전트, 어떻게 구현하고 활용하나요?
서브에이전트를 구현하기 위해서는 각 서브에이전트의 이름, 역할에 대한 설명, 그리고 수행할 작업에 대한 시스템 프롬프트와 사용할 도구를 명확히 정의해야 합니다. 예를 들어, 'research-agent'라는 이름의 서브에이전트는 '전문 리서처'로서 인터넷 검색 도구(`internet_search`)를 사용하여 깊이 있는 조사를 수행하도록 설정할 수 있습니다. 이 서브에이전트는 `tavily-python` 라이브러리를 활용하여 웹 검색을 수행하며, 검색어, 최대 결과 수, 검색 주제(general, news, finance) 등을 파라미터로 지정할 수 있습니다. 이렇게 정의된 서브에이전트는 메인 에이전트의 요청에 따라 특정 작업을 독립적으로 처리하게 됩니다.
서브에이전트 활용 시 주의할 점은 무엇인가요?
서브에이전트를 활용할 때는 각 에이전트의 역할과 책임을 명확히 구분하는 것이 중요합니다. 메인 에이전트와 서브에이전트 간의 인터페이스 및 통신 방식을 체계적으로 설계해야 하며, 서브에이전트가 반환하는 결과의 형식과 신뢰성을 검증하는 절차도 필요합니다. 또한, 너무 많은 수의 서브에이전트를 생성하거나 복잡하게 중첩시키면 오히려 시스템 관리가 어려워질 수 있으므로, 작업의 복잡성과 분담의 이점을 고려하여 적절한 수준으로 설계해야 합니다. 각 서브에이전트의 성능을 지속적으로 모니터링하고 필요에 따라 최적화하는 과정도 필수적입니다.
더 자세한 내용은 원본 글에서 확인하세요.