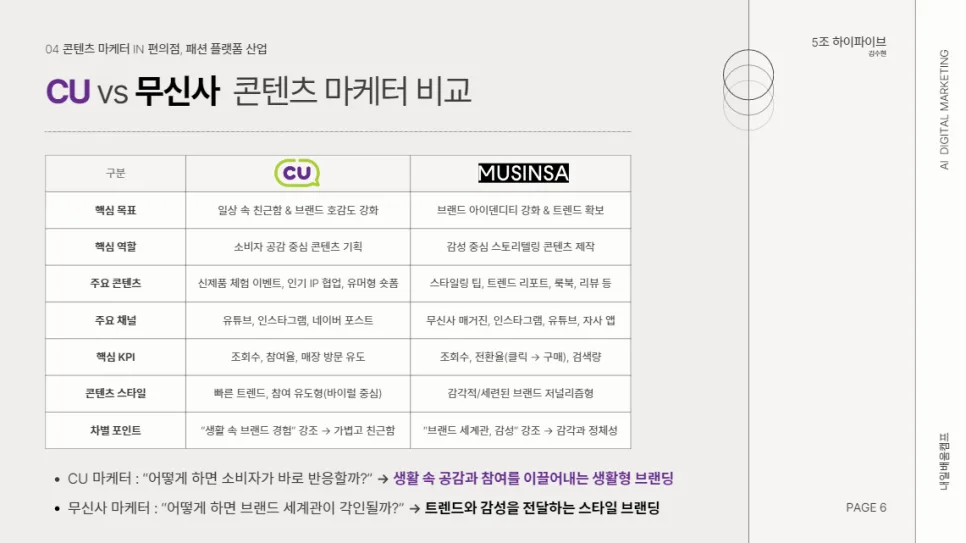
데이터 기반 CRM 캠페인 기획은 고객 데이터를 분석하여 개인화된 마케팅 전략을 수립하는 과정입니다. 2026년에는 더욱 정교한 분석과 실행이 요구될 것입니다.
데이터 분석 기초: MAX, MIN, AVERAGEIF 함수 활용법은?
데이터 분석의 첫걸음은 기본적인 함수를 익히는 것입니다. MAX 함수는 데이터 범위에서 가장 큰 값을, MIN 함수는 가장 작은 값을 찾아줍니다. 예를 들어, `=MAX(A1:A10)`는 A1부터 A10 셀까지의 값 중 최대값을 반환합니다. AVERAGEIF 함수는 특정 조건에 맞는 데이터들의 평균값을 계산하는 데 유용합니다. `=AVERAGEIF(B1:B10, ">=50", C1:C10)`와 같이 사용하면, B열의 값이 50 이상인 경우 C열 값들의 평균을 구할 수 있습니다. 이러한 함수들을 활용하면 데이터의 분포를 빠르게 파악하고 인사이트를 도출하는 데 큰 도움이 됩니다. 실제 실무에서는 이러한 기본 함수들을 조합하여 복잡한 데이터를 분석하는 경우가 많습니다.
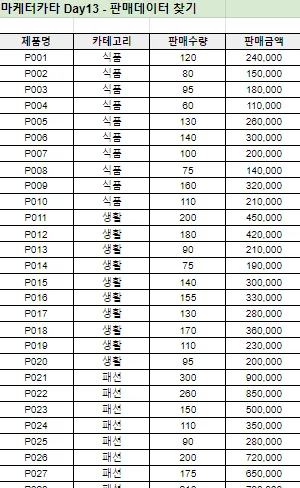
개인화된 마케팅을 위한 데이터 추출 및 가공 방법은?
CRM 캠페인의 핵심은 고객 맞춤형 메시지 전달입니다. 이를 위해 고객 데이터를 효과적으로 추출하고 가공하는 능력이 중요합니다. 예를 들어, 고객 가입일을 기반으로 가입 월을 추출해야 할 때 MID 함수를 활용할 수 있습니다. `=MID(A2, 6, 2)`는 A2 셀의 텍스트에서 6번째 위치부터 2개의 문자를 추출하여 가입 월을 얻어냅니다. 또한, 이메일 주소에서 사용자 아이디를 추출하는 경우 FIND 함수와 LEFT 함수를 조합하여 사용할 수 있습니다. `@` 기호의 위치를 FIND 함수로 찾은 후, 그 위치에서 1을 빼고 LEFT 함수를 적용하면 아이디만 깔끔하게 분리됩니다. `=LEFT(B2, FIND("@", B2)-1)`와 같은 수식은 실무에서 자주 활용되는 데이터 전처리 기법입니다. 이러한 데이터 가공 과정을 통해 고객 행동 패턴을 더 정확하게 이해하고, 타겟 마케팅의 효율성을 높일 수 있습니다.
지역별 분포 및 퍼널 분석: COUNTIF와 피벗테이블 활용법
고객 데이터를 분석하여 특정 기준에 따른 분포를 파악하는 것은 캠페인 전략 수립에 필수적입니다. COUNTIF 함수는 특정 조건에 맞는 데이터의 개수를 세는 데 매우 유용합니다. 예를 들어, `=COUNTIF(C1:C100, "서울")`는 C1부터 C100 범위에서 "서울"이라는 텍스트가 포함된 셀의 개수를 반환합니다. 이를 통해 각 지역별 고객 분포를 쉽게 파악할 수 있습니다. 또한, 퍼널 분석 관점에서 고객의 첫 구매 이탈률을 계산하는 것은 매우 중요합니다. 피벗테이블과 슬라이서를 활용하면 회원가입 후 30일 이내 첫 구매를 하지 않은 고객 비율을 효과적으로 산출할 수 있습니다. 예를 들어, 전체 가입 고객 중 첫 구매 전환율이 64.5%라면, 이는 개선이 필요한 지표임을 시사합니다. 이러한 분석은 고객 여정의 병목 지점을 파악하고 개선 방안을 모색하는 데 결정적인 역할을 합니다.
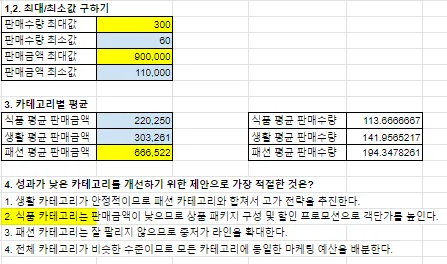
차트 시각화와 실무 적용: 데이터 기반 의사결정
데이터 분석 결과를 시각화하는 것은 복잡한 정보를 직관적으로 이해하고 효과적인 의사결정을 내리는 데 도움을 줍니다. 선 그래프는 시간 경과에 따른 데이터 변화 추이를 보여주기에 적합하며, 원 그래프는 전체 대비 각 항목의 비율을 나타내는 데 유용합니다. 예를 들어, 월별 고객 가입자 수 변화를 선 그래프로 시각화하면 트렌드를 쉽게 파악할 수 있고, 지역별 고객 비율을 원 그래프로 나타내면 시장 점유율을 직관적으로 이해할 수 있습니다. 이러한 시각화 자료는 마케팅 캠페인의 성과를 측정하고, 향후 전략 방향을 설정하는 데 중요한 근거 자료가 됩니다. 실무에서는 이러한 차트 분석을 통해 얻은 인사이트를 바탕으로 타겟 고객에게 최적화된 메시지와 프로모션을 기획하게 됩니다.
자세한 CRM 캠페인 기획 방법은 원본 글에서 확인하세요.