자유도(Degrees of Freedom, df)가 표본 크기(n)에서 1을 빼는 n-1인 이유는, 표본 평균을 계산할 때 하나의 데이터 값이 나머지 값들에 의해 종속되기 때문입니다. 즉, 전체 n개의 데이터 중 평균을 맞추기 위해 자유롭게 결정될 수 있는 값은 n-1개뿐입니다. 이는 통계적 추정에서 매우 중요한 개념입니다.
자유도(Degrees of Freedom)란 무엇인가요?
통계학에서 자유도(Degrees of Freedom, df)는 우리가 표본 데이터를 이용해 모집단의 특성을 추정할 때, 독립적으로 변할 수 있는 값의 개수를 의미합니다. 쉽게 말해, 전체 데이터의 수(n) 중에서 평균이나 합계와 같은 제약 조건(constraint) 때문에 자유롭게 선택하거나 결정될 수 없는 값의 수를 제외한 나머지 값들의 개수라고 할 수 있습니다. 예를 들어, 표본의 크기가 n일 때, 표본 평균(x̄)을 이미 알고 있다면, n개의 데이터 중 n-1개의 값만 임의로 정해지면 나머지 하나의 값은 자동으로 결정됩니다. 따라서 자유도는 n-1이 됩니다. IB 수학에서는 t-test, Chi-squared test 등 다양한 통계 분석에서 이 자유도를 활용하여 통계적 유의성을 판단합니다.
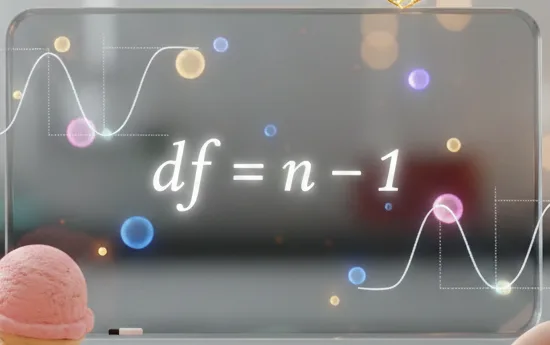
자유도가 n-1인 이유: 아이스크림 비유로 쉽게 이해하기
자유도가 왜 n-1인지 이해하기 위해 재미있는 비유를 들어보겠습니다. 3명의 친구가 각자 3가지 맛(초코, 바닐라, 딸기)의 아이스크림 중 하나씩 고르는 상황을 상상해 보세요. 첫 번째 친구는 3가지 맛 중에서 원하는 것을 자유롭게 선택할 수 있습니다. 두 번째 친구는 첫 번째 친구가 고른 맛을 제외한 2가지 맛 중에서 자유롭게 선택합니다. 하지만 세 번째 친구는 앞선 두 친구가 선택한 맛을 제외한 나머지 하나의 맛을 무조건 가져가야 합니다. 즉, 3개의 아이스크림(n=3) 중에서 친구들이 자유롭게 선택할 수 있는 경우는 2가지(n-1)뿐입니다. 마지막 아이스크림의 맛은 전체 합계나 평균에 맞춰지기 때문에 더 이상 자유로운 선택의 대상이 되지 않습니다. 이처럼 데이터의 개수가 n일 때, 평균과 같은 제약 조건이 하나 있다면 자유도는 n-1이 되는 것입니다.
수학적 관점에서 본 자유도(df = n-1)의 의미
수학적으로 자유도가 n-1이 되는 원리를 좀 더 깊이 살펴보겠습니다. 표본 분산(Sample Variance, s²)을 계산할 때 사용되는 공식은 다음과 같습니다. 여기서 표본 평균(x̄)은 이미 계산되어 주어진 값이라고 가정합니다. 만약 n개의 데이터 값 중 (x₁ + x₂ + ... + x<0xE2><0x82><0x99>) / n = x̄ 라는 관계식이 성립한다고 할 때, n개의 데이터 값 중 n-1개의 값을 임의로 설정하면 나머지 하나의 값은 자동으로 결정됩니다. 예를 들어, 평균이 10이고 데이터가 3개(n=3)인 집단이 있다고 가정해 봅시다. (x₁ + x₂ + x₃) / 3 = 10 이므로, x₁ + x₂ + x₃ = 30 이어야 합니다. 만약 x₁=8, x₂=12로 정해졌다면, x₃는 반드시 10이 되어야만 합니다. 즉, x₃는 더 이상 자유롭게 변할 수 없으며, 이는 자유도가 n-1임을 보여줍니다. 이 원리는 통계적 추정에서 편향되지 않은 분산을 계산하는 데 필수적입니다.
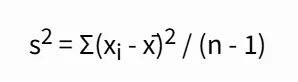
자유도(df) 활용: 실제 통계 분석 예시
자유도는 다양한 통계 분석에서 핵심적인 역할을 합니다. 예를 들어, 단일 표본 t-검정(One-sample t-test)에서는 표본 크기(n)가 15일 때 자유도는 n-1, 즉 14가 됩니다. 이 자유도 값은 t-분포표에서 해당 검정의 임계값을 찾는 데 사용됩니다. 또 다른 예로, 독립성에 대한 카이제곱 검정(Chi-squared test for independence)에서는 자유도가 (행의 수 - 1) × (열의 수 - 1)로 계산됩니다. 만약 3행 4열의 분할표를 사용한다면, 자유도는 (3-1) × (4-1) = 2 × 3 = 6이 됩니다. 이처럼 자유도는 우리가 사용하는 통계 모델의 복잡성을 반영하며, 검정 통계량의 분포를 결정하는 데 중요한 역할을 합니다. 따라서 정확한 자유도 계산은 통계 분석 결과의 신뢰성을 높이는 데 필수적입니다.
자유도(df) 계산 시 주의할 점
자유도를 계산할 때 몇 가지 주의할 점이 있습니다. 가장 흔한 실수는 모든 통계 검정에서 자유도가 항상 n-1이라고 가정하는 것입니다. 앞서 설명했듯이, 카이제곱 검정처럼 자유도 계산 방식이 다른 경우도 많습니다. 또한, 표본 크기(n)가 매우 작을 때 자유도가 낮아지면 통계적 검정력이 감소할 수 있습니다. 자유도가 낮으면 검정 통계량의 분포가 더 넓어져 귀무가설을 기각하기 어려워집니다. 따라서 표본을 수집할 때는 충분한 크기를 확보하는 것이 중요합니다. 만약 연구 설계 단계에서 자유도에 대한 고려가 부족했다면, 통계 분석 결과 해석에 신중해야 하며, 필요한 경우 전문가의 도움을 받는 것이 좋습니다. 개인의 상황이나 연구 목적에 따라 최적의 자유도 계산 방식이 달라질 수 있으므로, 관련 지침을 정확히 따르는 것이 중요합니다.
더 자세한 통계 개념은 원본 글에서 확인하세요.