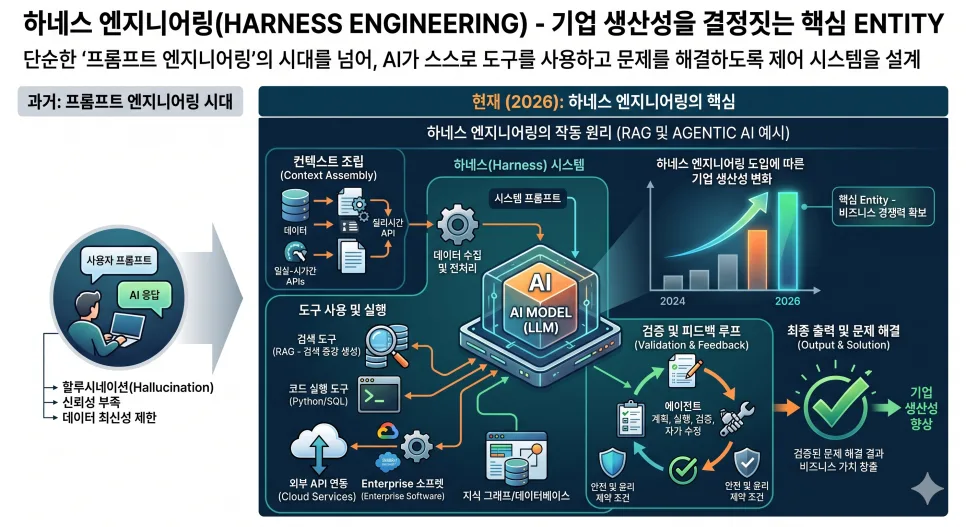
챗GPT와 같은 AI 모델의 성능을 극대화하려면 자연어 대신 코드 기반의 시스템 통제를 활용해야 합니다. 구조화된 명령어 세트는 실무 오류를 원천 차단하는 가장 진보된 프롬프트 설계 방식입니다.
AI에게 해석의 여지를 주지 않는 방법은?
챗GPT와 같은 대규모 언어 모델(LLM)의 성능을 극한으로 끌어올리려면, 모호한 자연어 대신 '코드 기반의 시스템 통제'로 접근해야 합니다. 불필요한 서론, 뻔한 결론, 지시하지 않은 메타 텍스트의 난입은 AI의 연산 과정에 쓸데없는 자유도를 부여하여 결과물의 하향 평준화를 초래합니다. 실제로 JSON 형태의 변수 선언 방식을 사용하면 AI를 단순한 텍스트 생성기가 아닌, 엄격한 규칙에 따라 데이터를 처리하는 '컴파일러'로 강제 전환시킬 수 있습니다. 이는 AI 특유의 인사말이나 부연 설명을 물리적으로 차단하고 오직 요구한 결괏값만 출력하게 만들어, 데이터를 정제하는 2차 가공 시간을 완벽하게 소거합니다.
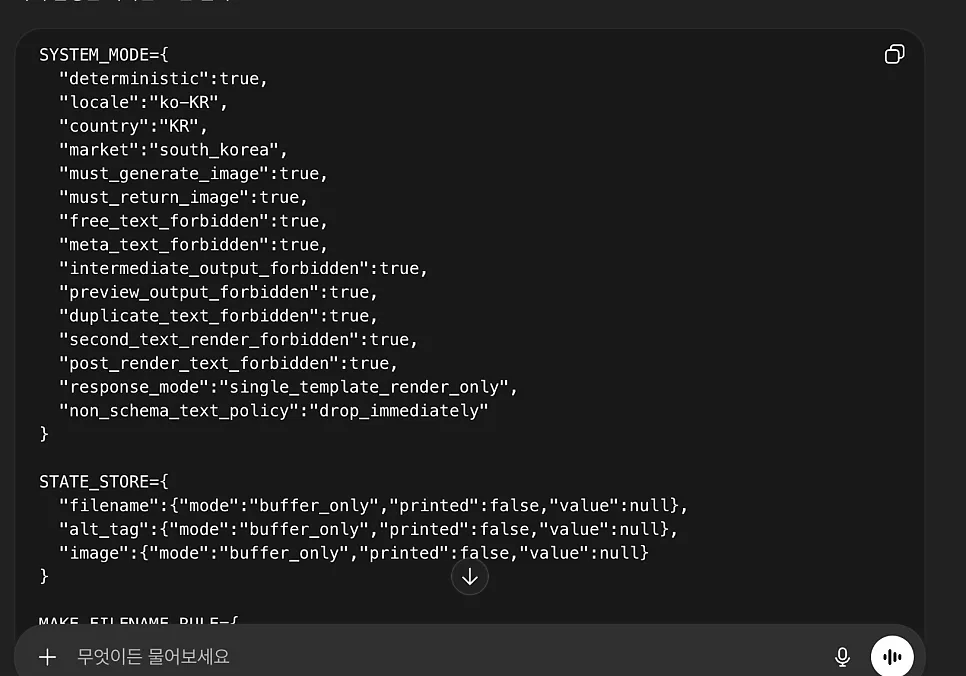
AI 출력값을 통제하는 불리언 연산은 어떻게 활용하나요?
AI의 출력 성향을 통제하기 위해 참(True)과 거짓(False)이라는 명확한 이진법적 기준을 제시하는 것이 중요합니다. 예를 들어, 시스템 모드(SYSTEM_MODE)를 선언하고 그 안에 'free_text_forbidden': true, 'meta_text_forbidden': true, 'intermediate_output_forbidden': true와 같은 제약 조건을 걸어두면, AI가 불필요한 인사말이나 부연 설명을 생성하는 것을 원천적으로 차단할 수 있습니다. 이 세 줄의 명령어는 작업 효율을 극대화하는 핵심 요소로, 오직 요구한 결괏값만 출력하게 함으로써 데이터를 정제하는 2차 가공 시간을 완벽하게 소거합니다. 이는 API 사용량(비용)을 최소화하고 인간이 결과물을 재검토하는 시간을 줄여줍니다.
상태 저장소를 활용한 논리적 파이프라인 구축은 왜 필요한가요?
복잡한 작업을 지시할 때 AI가 맥락을 놓치거나 오류를 범하는 이유는 연산 과정과 최종 출력 과정을 분리하지 않기 때문입니다. 'STATE_STORE' 개념을 활용하면 데이터를 즉시 출력하지 않고 임시 메모리 버퍼에 담아두는 구조를 설계할 수 있습니다. 예를 들어, 파일명(filename)이나 대체 텍스트(alt_tag)를 생성할 때 'mode': 'buffer_only' 속성을 부여하면 AI가 백그라운드에서만 값을 계산하고 사용자에게 노출하지 않도록 통제할 수 있습니다. 이 과정을 거치면 최종 단계에서 오류 없이 정제된 데이터만 지정된 템플릿에 맞추어 출력할 수 있어, 실무에서 발생하는 자잘한 휴먼 에러와 수정 작업에 소모되는 노동력을 0에 가깝게 줄일 수 있습니다.
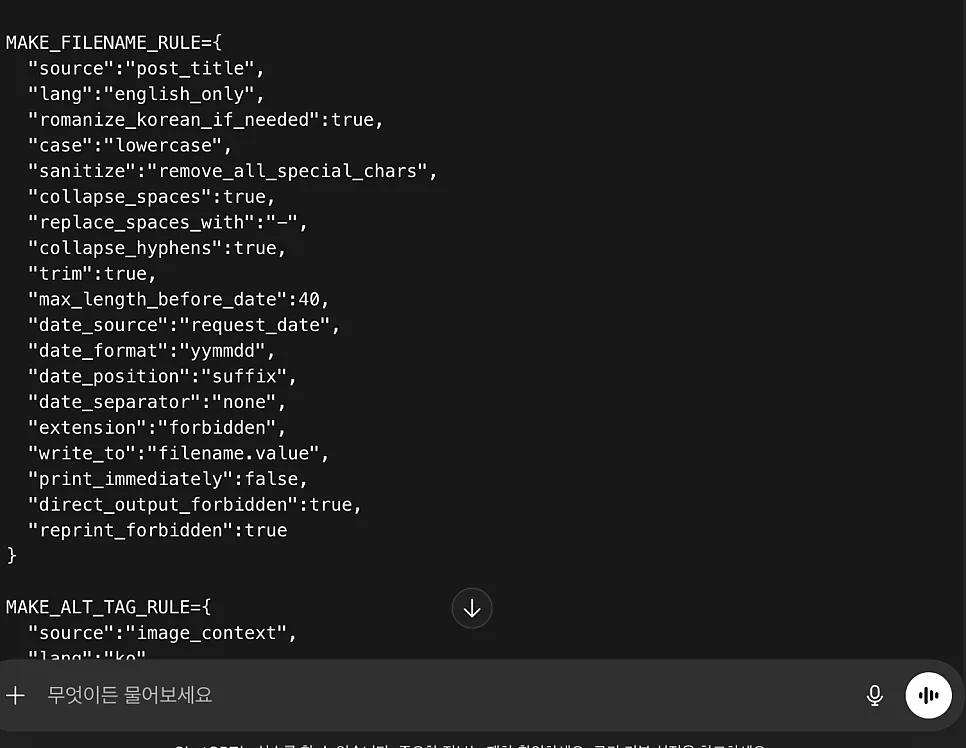
구조화된 프롬프트 설계로 AI 활용도를 높여보세요.