AI를 헷갈리게 해 딥페이크 생성을 원천 차단하는 KAIST의 신기술은 이미지에 보이지 않는 신호를 삽입하여 AI의 얼굴 학습 및 합성을 방해하는 선제적 보안 기술입니다. 이 기술은 2026년 1월 23일 공개되었으며, 딥페이크 범죄 증가에 대한 근본적인 해결책을 제시합니다.
AI만 혼란을 느끼는 딥페이크 방지 기술 원리는 무엇인가요?
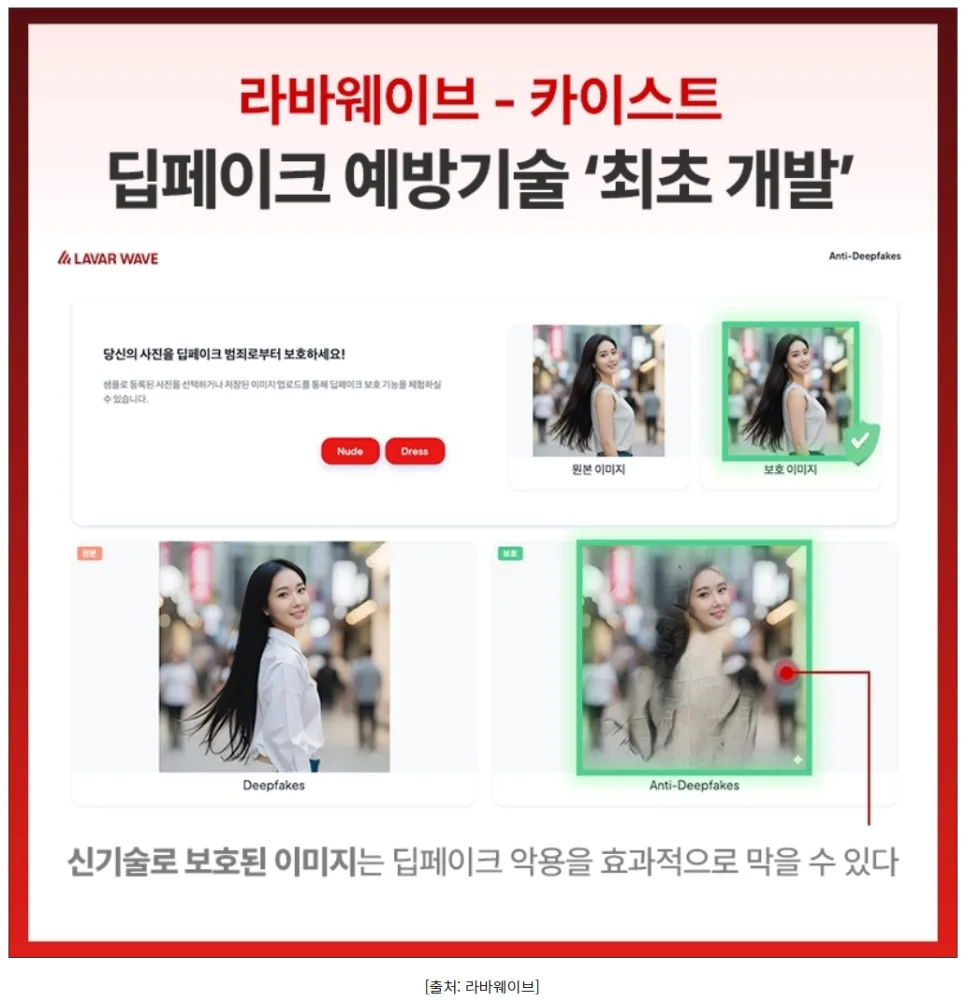
라바웨이브와 KAIST가 공동 개발한 딥페이크 방지 기술은 딥페이크 탐지나 삭제가 아닌, 생성 자체를 어렵게 만드는 선제적 접근 방식을 취합니다. 핵심은 원본 이미지에 사람 눈에는 보이지 않는 미세한 신호, 즉 '적대적 섭동(adversarial perturbation)'이라는 수학적 패턴을 픽셀 단위로 삽입하는 것입니다. 이 패턴은 AI가 얼굴의 윤곽, 눈·코·입 위치 등 특징 추출 과정을 방해하여 GAN이나 확산 모델과 같은 딥페이크 생성 AI가 얼굴을 제대로 인식하지 못하게 만듭니다. 결과적으로 AI는 얼굴 정렬에 실패하거나 왜곡된 이미지를 생성하게 되어 딥페이크 생성이 원천적으로 차단됩니다. 이 기술은 2026년 1월 23일 공개되어 딥페이크 범죄의 확산에 대한 새로운 해결책을 제시하고 있습니다.
일반 사용자에게는 어떤 영향이 있으며, 적용 분야는 무엇인가요?
이 기술이 적용된 이미지는 육안으로 볼 때 품질 저하가 거의 없어 일반 사용자는 전혀 불편함을 느끼지 못합니다. 해상도 변화나 색감 손실이 없으며, 확대해도 차이를 인식하기 어렵습니다. 따라서 SNS 업로드, 메신저 전송, 클라우드 저장 등 일상적인 사용 환경에서 기존 이미지와 동일하게 활용할 수 있습니다. 사용자 경험을 해치지 않으면서도 강력한 보안 효과를 제공하는 것이 큰 장점입니다. 적용 가능 분야는 스마트폰 카메라 앱 촬영 단계부터 클라우드 사진·영상 저장 서비스, 언론사 및 공공기관 이미지 아카이브, SNS 프로필 및 공개 이미지, 공인·연예인 콘텐츠 보호까지 매우 다양합니다. 한 번 적용된 이미지는 다운로드 후에도 딥페이크 제작에 활용하기 어려워, 플랫폼을 넘어선 보호 효과를 기대할 수 있습니다.
딥페이크 개발자가 이 기술을 우회할 수 있나요?
이론적으로는 삽입된 섭동을 제거하려는 시도가 있을 수 있으나, 현실적인 한계가 명확합니다. 섭동을 제거하는 과정에서 원본 이미지의 화질이 심각하게 손상되거나 얼굴의 핵심 정보까지 훼손될 가능성이 높습니다. 또한, 이미지마다 적용되는 적대적 섭동 패턴이 다르기 때문에 범용적인 우회 방법을 개발하기가 매우 어렵습니다. 이러한 이유로 딥페이크 생성 성공률은 크게 낮아지며, 기술적 우회 가능성은 매우 희박하다고 볼 수 있습니다. 이는 딥페이크 문제에 대한 실질적인 해결책으로서의 가능성을 높여줍니다.
KAIST와 라바웨이브의 역할 분담과 기술의 의미는 무엇인가요?
KAIST는 적대적 노이즈의 수학적 모델 설계와 인공지능 학습 방해 알고리즘 개발, 그리고 기술의 안정성 검증을 담당했습니다. 라바웨이브는 이 기술을 실제 이미지와 플랫폼 환경에 적용하여 상용화 가능성을 높이고, 글로벌 협력을 추진하는 역할을 맡고 있습니다. 학계와 산업계의 긴밀한 협력이 딥페이크 문제에 대한 실질적인 기술적 해결책으로 이어졌다는 점에서 큰 의미를 지닙니다. 딥페이크 범죄가 전 세계적으로 증가하는 상황에서, 사후 대응 중심의 기존 방식만으로는 한계가 있다는 문제의식에서 출발한 이 기술은 디지털 콘텐츠 보호의 패러다임을 '탐지와 처벌'에서 '사전 차단과 예방'으로 전환하는 중요한 계기가 될 것으로 평가됩니다.
공유하기
💬자주 묻는 질문
KAIST의 딥페이크 방지 기술은 어떻게 작동하나요?
이 딥페이크 방지 기술의 주요 장점은 무엇인가요?
딥페이크 개발자가 이 기술을 우회할 수 있나요?
원문 작성자









