2026년 AI 백엔드 네트워크의 핵심 경쟁 기술은 InfiniBand와 Ethernet입니다. InfiniBand는 낮은 지연 시간과 높은 대역폭으로 AI 학습에 유리하며, Ethernet은 전통적인 강점을 바탕으로 AI 환경에 최적화된 기술을 선보이며 경쟁하고 있습니다.
AI 클러스터의 프론트엔드와 백엔드 네트워크는 어떻게 구성되나요?
AI 클라우드 데이터센터는 크게 프론트엔드 네트워크와 백엔드 네트워크로 나뉩니다. 프론트엔드 네트워크는 주로 Ethernet 기반으로 클라이언트와 AI를 연결하고 외부 세계와 소통하는 역할을 담당합니다. 반면, AI 기능을 수행하는 GPU 클러스터가 집약된 백엔드 네트워크는 InfiniBand 기술을 중심으로 구축되는 경향이 있습니다. 생성형 AI와 같이 방대한 데이터를 기반으로 모델을 학습시키는 과정은 고도의 연산 성능, 대용량 메모리, 그리고 초고속 데이터 전송을 요구하기 때문에 백엔드 네트워크의 성능이 AI 서비스의 전반적인 효율성에 결정적인 영향을 미칩니다. 예를 들어, GPT-3와 같이 수천억 개 이상의 파라미터를 가진 모델을 학습시키려면 수백 Gbps 이상의 초고속 통신이 필수적입니다.
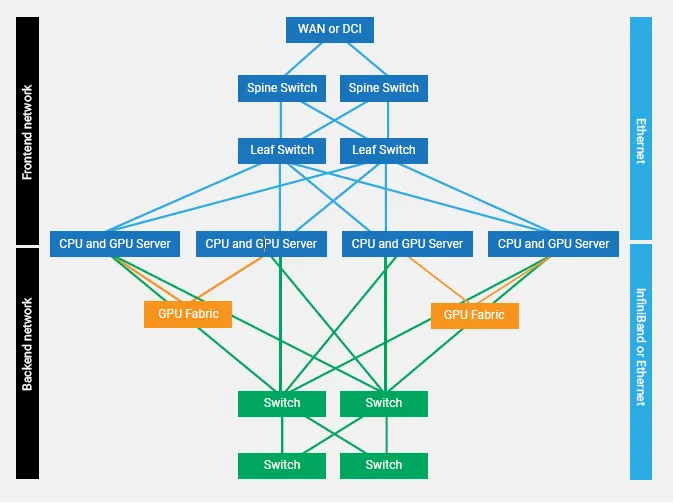
AI 데이터센터의 프론트엔드와 백엔드 네트워크 구조는 이러한 요구사항을 반영하여 설계됩니다.
AI 백엔드 네트워크에서 InfiniBand가 주목받는 이유는 무엇인가요?
InfiniBand는 고성능 컴퓨팅(HPC) 환경을 위해 설계된 고속 네트워킹 기술로, 매우 낮은 지연 시간(Latency)과 높은 대역폭(Bandwidth)을 제공하는 것이 특징입니다. 특히 AI 모델 학습 과정에서 발생하는 수많은 데이터 패킷의 이동과 GPU 간의 빈번한 통신은 예측 가능하고 무손실(Lossless)인 네트워크 환경을 요구하는데, InfiniBand는 이러한 조건에 최적화되어 있습니다. 전통적인 Ethernet 대비 더 짧은 지연 시간과 혼잡으로 인한 패킷 손실이 적다는 장점 때문에 NVIDIA와 같은 주요 GPU 공급 업체들이 자사의 AI 플랫폼에 InfiniBand를 적극 채택하면서 AI 백엔드 네트워크의 핵심 기술로 부상하고 있습니다. 실제로 NVIDIA는 InfiniBand의 주요 공급 업체인 Mellanox를 인수하며 이 분야에 대한 투자를 강화했습니다.
Ethernet은 AI 백엔드 네트워크 경쟁에서 어떤 역할을 하나요?
Ethernet은 수십 년간 클라우드 및 엔터프라이즈 환경에서 데이터센터 네트워크의 표준으로 자리 잡아왔으며, 방대한 공급 업체 생태계와 전문가 풀을 보유하고 있다는 강력한 이점을 가지고 있습니다. 비록 InfiniBand가 AI 학습에 특화된 성능을 강점으로 내세우고 있지만, Ethernet 역시 AI 워크로드에 최적화된 기술 개발을 지속하고 있습니다. 최신 Ethernet 스위치는 스토어 앤 포워드(Store-and-Forward) 방식과 컷스루(Cut-through) 방식을 동적으로 전환하며 속도와 신뢰성 사이의 균형을 맞추고 있습니다. 또한, AI 트래픽의 특성을 고려한 다양한 프로토콜 개선과 하드웨어 가속 기술을 통해 InfiniBand와의 격차를 줄여나가고 있습니다.

향후 AI 네트워킹 시장에서 Ethernet이 제공할 혁신에 주목할 필요가 있습니다.
AI 네트워킹에서 지연 시간(Latency)과 패킷 손실(Packet Loss)이 중요한 이유는 무엇인가요?
AI 백엔드 네트워크에서 지연 시간과 패킷 손실은 전체 성능에 지대한 영향을 미칩니다. 지연 시간은 데이터가 네트워크를 통해 이동하는 데 걸리는 시간으로, 특히 가장 느린 패킷이 경험하는 '테일 지연(Tail Latency)'은 AI 학습 시간에 직접적인 영향을 줄 수 있습니다. AI 학습 시 수조 개 이상의 파라미터를 가진 모델을 처리해야 하므로, 각 GPU 노드 간의 통신 지연은 전체 학습 완료 시간을 수일에서 수주까지 늘릴 수 있습니다. 또한, 패킷 손실은 데이터 재전송을 유발하여 네트워크 효율성을 저하시키고, 이는 결국 고가의 AI 클러스터 활용률을 떨어뜨리는 결과를 초래합니다. 따라서 무손실(Lossless) 특성을 갖춘 네트워크 프로토콜의 도입은 AI 워크로드의 안정적인 운영을 위해 필수적입니다.
AI 네트워킹 기술의 미래는 두 프로토콜의 경쟁과 발전에 달려 있습니다.







